sobol_indices#
- scipy.stats.sobol_indices(*, func, n, dists=None, method='saltelli_2010', rng=None, random_state=None)[source]#
Global sensitivity indices of Sobol’.
- Parameters:
- funccallable or dict(str, array_like)
If func is a callable, function to compute the Sobol’ indices from. Its signature must be:
func(x: ArrayLike) -> ArrayLike
with
xof shape(d, n)and output of shape(s, n)where:dis the input dimensionality of func (number of input variables),sis the output dimensionality of func (number of output variables), andnis the number of samples (see n below).
Function evaluation values must be finite.
If func is a dictionary, contains the function evaluations from three different arrays. Keys must be:
f_A,f_Bandf_AB.f_Aandf_Bshould have a shape(s, n)andf_ABshould have a shape(d, s, n). This is an advanced feature and misuse can lead to wrong analysis.- nint
Number of samples used to generate the matrices
AandB. Must be a power of 2. The total number of points at which func is evaluated will ben*(d+2).- distslist(distributions), optional
List of each parameter’s distribution. The distribution of parameters depends on the application and should be carefully chosen. Parameters are assumed to be independently distributed, meaning there is no constraint nor relationship between their values.
Distributions must be an instance of a class with a
ppfmethod.Must be specified if func is a callable, and ignored otherwise.
- methodCallable or str, default: ‘saltelli_2010’
Method used to compute the first and total Sobol’ indices.
If a callable, its signature must be:
func(f_A: np.ndarray, f_B: np.ndarray, f_AB: np.ndarray) -> tuple[np.ndarray, np.ndarray]
with
f_A, f_Bof shape(s, n)andf_ABof shape(d, s, n). These arrays contain the function evaluations from three different sets of samples. The output is a tuple of the first and total indices with shape(s, d). This is an advanced feature and misuse can lead to wrong analysis.- rng
numpy.random.Generator, optional Pseudorandom number generator state. When rng is None, a new
numpy.random.Generatoris created using entropy from the operating system. Types other thannumpy.random.Generatorare passed tonumpy.random.default_rngto instantiate aGenerator.Changed in version 1.15.0: As part of the SPEC-007 transition from use of
numpy.random.RandomStatetonumpy.random.Generator, this keyword was changed from random_state to rng. For an interim period, both keywords will continue to work, although only one may be specified at a time. After the interim period, function calls using the random_state keyword will emit warnings. Following a deprecation period, the random_state keyword will be removed.
- Returns:
- resSobolResult
An object with attributes:
- first_orderndarray of shape (s, d)
First order Sobol’ indices.
- total_orderndarray of shape (s, d)
Total order Sobol’ indices.
And method:
bootstrap(confidence_level: float, n_resamples: int) -> BootstrapSobolResult
A method providing confidence intervals on the indices. See
scipy.stats.bootstrapfor more details.The bootstrapping is done on both first and total order indices, and they are available in BootstrapSobolResult as attributes
first_orderandtotal_order.
Notes
The Sobol’ method [1], [2] is a variance-based Sensitivity Analysis which obtains the contribution of each parameter to the variance of the quantities of interest (QoIs; i.e., the outputs of func). Respective contributions can be used to rank the parameters and also gauge the complexity of the model by computing the model’s effective (or mean) dimension.
Note
Parameters are assumed to be independently distributed. Each parameter can still follow any distribution. In fact, the distribution is very important and should match the real distribution of the parameters.
It uses a functional decomposition of the variance of the function to explore
\[\mathbb{V}(Y) = \sum_{i}^{d} \mathbb{V}_i (Y) + \sum_{i<j}^{d} \mathbb{V}_{ij}(Y) + ... + \mathbb{V}_{1,2,...,d}(Y),\]introducing conditional variances:
\[\mathbb{V}_i(Y) = \mathbb{\mathbb{V}}[\mathbb{E}(Y|x_i)] \qquad \mathbb{V}_{ij}(Y) = \mathbb{\mathbb{V}}[\mathbb{E}(Y|x_i x_j)] - \mathbb{V}_i(Y) - \mathbb{V}_j(Y),\]Sobol’ indices are expressed as
\[S_i = \frac{\mathbb{V}_i(Y)}{\mathbb{V}[Y]} \qquad S_{ij} =\frac{\mathbb{V}_{ij}(Y)}{\mathbb{V}[Y]}.\]\(S_{i}\) corresponds to the first-order term which apprises the contribution of the i-th parameter, while \(S_{ij}\) corresponds to the second-order term which informs about the contribution of interactions between the i-th and the j-th parameters. These equations can be generalized to compute higher order terms; however, they are expensive to compute and their interpretation is complex. This is why only first order indices are provided.
Total order indices represent the global contribution of the parameters to the variance of the QoI and are defined as:
\[S_{T_i} = S_i + \sum_j S_{ij} + \sum_{j,k} S_{ijk} + ... = 1 - \frac{\mathbb{V}[\mathbb{E}(Y|x_{\sim i})]}{\mathbb{V}[Y]}.\]First order indices sum to at most 1, while total order indices sum to at least 1. If there are no interactions, then first and total order indices are equal, and both first and total order indices sum to 1.
Warning
Negative Sobol’ values are due to numerical errors. Increasing the number of points n should help.
The number of sample required to have a good analysis increases with the dimensionality of the problem. e.g. for a 3 dimension problem, consider at minima
n >= 2**12. The more complex the model is, the more samples will be needed.Even for a purely additive model, the indices may not sum to 1 due to numerical noise.
References
[1]Sobol, I. M.. “Sensitivity analysis for nonlinear mathematical models.” Mathematical Modeling and Computational Experiment, 1:407-414, 1993.
[2]Sobol, I. M. (2001). “Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates.” Mathematics and Computers in Simulation, 55(1-3):271-280, DOI:10.1016/S0378-4754(00)00270-6, 2001.
[3]Saltelli, A. “Making best use of model evaluations to compute sensitivity indices.” Computer Physics Communications, 145(2):280-297, DOI:10.1016/S0010-4655(02)00280-1, 2002.
[4]Saltelli, A., M. Ratto, T. Andres, F. Campolongo, J. Cariboni, D. Gatelli, M. Saisana, and S. Tarantola. “Global Sensitivity Analysis. The Primer.” 2007.
[5]Saltelli, A., P. Annoni, I. Azzini, F. Campolongo, M. Ratto, and S. Tarantola. “Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index.” Computer Physics Communications, 181(2):259-270, DOI:10.1016/j.cpc.2009.09.018, 2010.
[6]Ishigami, T. and T. Homma. “An importance quantification technique in uncertainty analysis for computer models.” IEEE, DOI:10.1109/ISUMA.1990.151285, 1990.
Examples
The following is an example with the Ishigami function [6]
\[Y(\mathbf{x}) = \sin x_1 + 7 \sin^2 x_2 + 0.1 x_3^4 \sin x_1,\]with \(\mathbf{x} \in [-\pi, \pi]^3\). This function exhibits strong non-linearity and non-monotonicity.
Remember, Sobol’ indices assumes that samples are independently distributed. In this case we use a uniform distribution on each marginals.
>>> import numpy as np >>> from scipy.stats import sobol_indices, uniform >>> rng = np.random.default_rng() >>> def f_ishigami(x): ... f_eval = ( ... np.sin(x[0]) ... + 7 * np.sin(x[1])**2 ... + 0.1 * (x[2]**4) * np.sin(x[0]) ... ) ... return f_eval >>> indices = sobol_indices( ... func=f_ishigami, n=1024, ... dists=[ ... uniform(loc=-np.pi, scale=2*np.pi), ... uniform(loc=-np.pi, scale=2*np.pi), ... uniform(loc=-np.pi, scale=2*np.pi) ... ], ... rng=rng ... ) >>> indices.first_order array([0.31637954, 0.43781162, 0.00318825]) >>> indices.total_order array([0.56122127, 0.44287857, 0.24229595])
Confidence interval can be obtained using bootstrapping.
>>> boot = indices.bootstrap()
Then, this information can be easily visualized.
>>> import matplotlib.pyplot as plt >>> fig, axs = plt.subplots(1, 2, figsize=(9, 4)) >>> _ = axs[0].errorbar( ... [1, 2, 3], indices.first_order, fmt='o', ... yerr=[ ... indices.first_order - boot.first_order.confidence_interval.low, ... boot.first_order.confidence_interval.high - indices.first_order ... ], ... ) >>> axs[0].set_ylabel("First order Sobol' indices") >>> axs[0].set_xlabel('Input parameters') >>> axs[0].set_xticks([1, 2, 3]) >>> _ = axs[1].errorbar( ... [1, 2, 3], indices.total_order, fmt='o', ... yerr=[ ... indices.total_order - boot.total_order.confidence_interval.low, ... boot.total_order.confidence_interval.high - indices.total_order ... ], ... ) >>> axs[1].set_ylabel("Total order Sobol' indices") >>> axs[1].set_xlabel('Input parameters') >>> axs[1].set_xticks([1, 2, 3]) >>> plt.tight_layout() >>> plt.show()
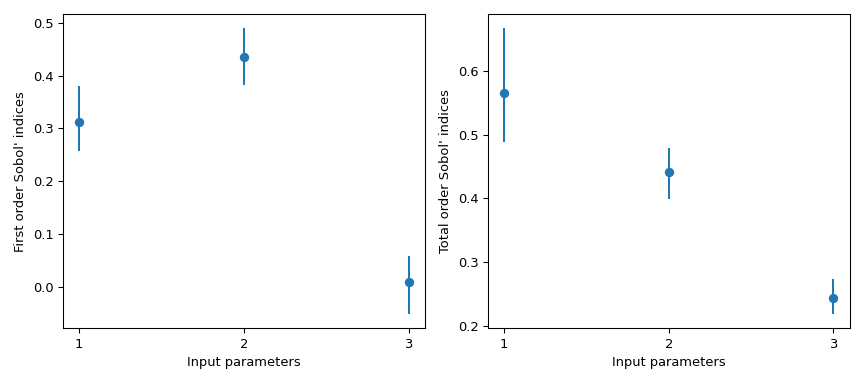
Note
By default,
scipy.stats.uniformhas support[0, 1]. Using the parameterslocandscale, one obtains the uniform distribution on[loc, loc + scale].This result is particularly interesting because the first order index \(S_{x_3} = 0\) whereas its total order is \(S_{T_{x_3}} = 0.244\). This means that higher order interactions with \(x_3\) are responsible for the difference. Almost 25% of the observed variance on the QoI is due to the correlations between \(x_3\) and \(x_1\), although \(x_3\) by itself has no impact on the QoI.
The following gives a visual explanation of Sobol’ indices on this function. Let’s generate 1024 samples in \([-\pi, \pi]^3\) and calculate the value of the output.
>>> from scipy.stats import qmc >>> n_dim = 3 >>> p_labels = ['$x_1$', '$x_2$', '$x_3$'] >>> sample = qmc.Sobol(d=n_dim, seed=rng).random(1024) >>> sample = qmc.scale( ... sample=sample, ... l_bounds=[-np.pi, -np.pi, -np.pi], ... u_bounds=[np.pi, np.pi, np.pi] ... ) >>> output = f_ishigami(sample.T)
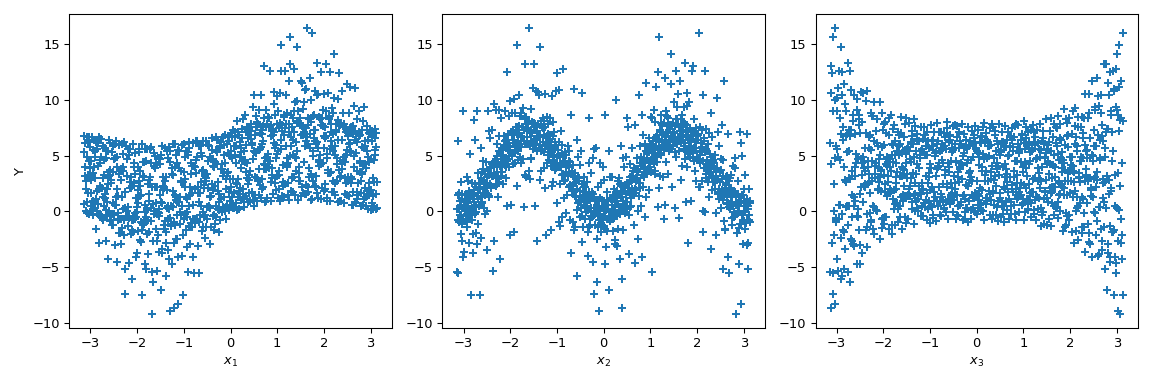
Now we can do scatter plots of the output with respect to each parameter. This gives a visual way to understand how each parameter impacts the output of the function.
>>> fig, ax = plt.subplots(1, n_dim, figsize=(12, 4)) >>> for i in range(n_dim): ... xi = sample[:, i] ... ax[i].scatter(xi, output, marker='+') ... ax[i].set_xlabel(p_labels[i]) >>> ax[0].set_ylabel('Y') >>> plt.tight_layout() >>> plt.show()
Now Sobol’ goes a step further: by conditioning the output value by given values of the parameter (black lines), the conditional output mean is computed. It corresponds to the term \(\mathbb{E}(Y|x_i)\). Taking the variance of this term gives the numerator of the Sobol’ indices.
>>> mini = np.min(output) >>> maxi = np.max(output) >>> n_bins = 10 >>> bins = np.linspace(-np.pi, np.pi, num=n_bins, endpoint=False) >>> dx = bins[1] - bins[0] >>> fig, ax = plt.subplots(1, n_dim, figsize=(12, 4)) >>> for i in range(n_dim): ... xi = sample[:, i] ... ax[i].scatter(xi, output, marker='+') ... ax[i].set_xlabel(p_labels[i]) ... for bin_ in bins: ... idx = np.where((bin_ <= xi) & (xi <= bin_ + dx)) ... xi_ = xi[idx] ... y_ = output[idx] ... ave_y_ = np.mean(y_) ... ax[i].plot([bin_ + dx/2] * 2, [mini, maxi], c='k') ... ax[i].scatter(bin_ + dx/2, ave_y_, c='r') >>> ax[0].set_ylabel('Y') >>> plt.tight_layout() >>> plt.show()
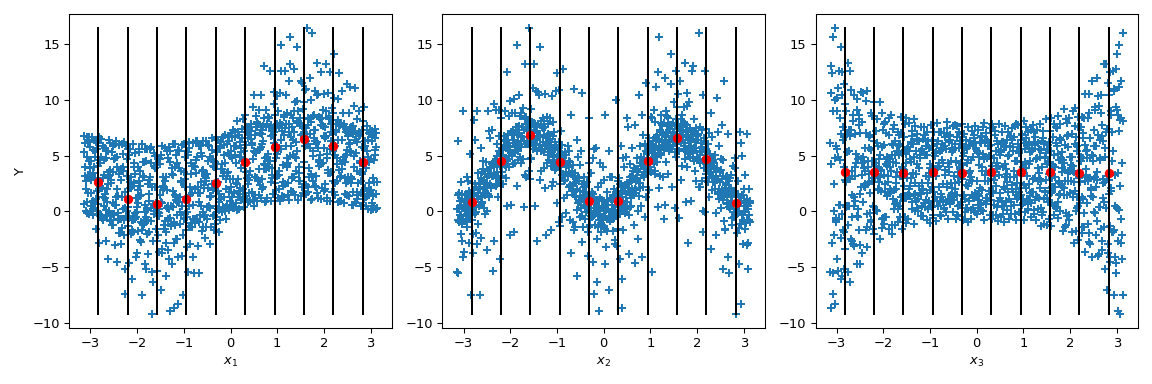
Looking at \(x_3\), the variance of the mean is zero leading to \(S_{x_3} = 0\). But we can further observe that the variance of the output is not constant along the parameter values of \(x_3\). This heteroscedasticity is explained by higher order interactions. Moreover, a heteroscedasticity is also noticeable on \(x_1\) leading to an interaction between \(x_3\) and \(x_1\). On \(x_2\), the variance seems to be constant and thus null interaction with this parameter can be supposed.
This case is fairly simple to analyse visually—although it is only a qualitative analysis. Nevertheless, when the number of input parameters increases such analysis becomes unrealistic as it would be difficult to conclude on high-order terms. Hence the benefit of using Sobol’ indices.