curve_fit#
- scipy.optimize.curve_fit(f, xdata, ydata, p0=None, sigma=None, absolute_sigma=False, check_finite=None, bounds=(-inf, inf), method=None, jac=None, *, full_output=False, nan_policy=None, **kwargs)[source]#
Use non-linear least squares to fit a function, f, to data.
Assumes
ydata = f(xdata, *params) + eps.- Parameters:
- fcallable
The model function, f(x, …). It must take the independent variable as the first argument and the parameters to fit as separate remaining arguments.
- xdataarray_like
The independent variable where the data is measured. Should usually be an M-length sequence or an (k,M)-shaped array for functions with k predictors, and each element should be float convertible if it is an array like object.
- ydataarray_like
The dependent data, a length M array - nominally
f(xdata, ...).- p0array_like, optional
Initial guess for the parameters (length N). If None, then the initial values will all be 1 (if the number of parameters for the function can be determined using introspection, otherwise a ValueError is raised).
- sigmaNone or scalar or M-length sequence or MxM array, optional
Determines the uncertainty in ydata. If we define residuals as
r = ydata - f(xdata, *popt), then the interpretation of sigma depends on its number of dimensions:A scalar or 1-D sigma should contain values of standard deviations of errors in ydata. In this case, the optimized function is
chisq = sum((r / sigma) ** 2).A 2-D sigma should contain the covariance matrix of errors in ydata. In this case, the optimized function is
chisq = r.T @ inv(sigma) @ r.Added in version 0.19.
None (default) is equivalent of 1-D sigma filled with ones.
- absolute_sigmabool, optional
If True, sigma is used in an absolute sense and the estimated parameter covariance pcov reflects these absolute values.
If False (default), only the relative magnitudes of the sigma values matter. The returned parameter covariance matrix pcov is based on scaling sigma by a constant factor. This constant is set by demanding that the reduced chisq for the optimal parameters popt when using the scaled sigma equals unity. In other words, sigma is scaled to match the sample variance of the residuals after the fit. Default is False. Mathematically,
pcov(absolute_sigma=False) = pcov(absolute_sigma=True) * chisq(popt)/(M-N)- check_finitebool, optional
If True, check that the input arrays do not contain nans of infs, and raise a ValueError if they do. Setting this parameter to False may silently produce nonsensical results if the input arrays do contain nans. Default is True if nan_policy is not specified explicitly and False otherwise.
- bounds2-tuple of array_like or
Bounds, optional Lower and upper bounds on parameters. Defaults to no bounds. There are two ways to specify the bounds:
Instance of
Boundsclass.2-tuple of array_like: Each element of the tuple must be either an array with the length equal to the number of parameters, or a scalar (in which case the bound is taken to be the same for all parameters). Use
np.infwith an appropriate sign to disable bounds on all or some parameters.
- method{‘lm’, ‘trf’, ‘dogbox’}, optional
Method to use for optimization. See
least_squaresfor more details. Default is ‘lm’ for unconstrained problems and ‘trf’ if bounds are provided. The method ‘lm’ won’t work when the number of observations is less than the number of variables, use ‘trf’ or ‘dogbox’ in this case.Added in version 0.17.
- jaccallable, str or None, optional
Function with signature
jac(x, ...)which computes the Jacobian matrix of the model function with respect to parameters as a dense array_like structure. It will be scaled according to provided sigma. If None (default), the Jacobian will be estimated numerically. String keywords for ‘trf’ and ‘dogbox’ methods can be used to select a finite difference scheme, seeleast_squares.Added in version 0.18.
- full_outputbool, optional
If True, this function returns additional information: infodict, mesg, and ier.
Added in version 1.9.
- nan_policy{‘raise’, ‘omit’, None}, optional
Defines how to handle when input contains nan. The following options are available (default is None):
‘raise’: throws an error
‘omit’: performs the calculations ignoring nan values
None: no special handling of NaNs is performed (except what is done by check_finite); the behavior when NaNs are present is implementation-dependent and may change.
Note that if this value is specified explicitly (not None), check_finite will be set as False.
Added in version 1.11.
- **kwargs
Keyword arguments passed to
leastsqformethod='lm'orleast_squaresotherwise.
- Returns:
- poptarray
Optimal values for the parameters so that the sum of the squared residuals of
f(xdata, *popt) - ydatais minimized.- pcov2-D array
The estimated approximate covariance of popt. The diagonals provide the variance of the parameter estimate. To compute one standard deviation errors on the parameters, use
perr = np.sqrt(np.diag(pcov)). Note that the relationship between cov and parameter error estimates is derived based on a linear approximation to the model function around the optimum [1]. When this approximation becomes inaccurate, cov may not provide an accurate measure of uncertainty.How the sigma parameter affects the estimated covariance depends on absolute_sigma argument, as described above.
If the Jacobian matrix at the solution doesn’t have a full rank, then ‘lm’ method returns a matrix filled with
np.inf, on the other hand ‘trf’ and ‘dogbox’ methods use Moore-Penrose pseudoinverse to compute the covariance matrix. Covariance matrices with large condition numbers (e.g. computed withnumpy.linalg.cond) may indicate that results are unreliable.- infodictdict (returned only if full_output is True)
a dictionary of optional outputs with the keys:
nfevThe number of function calls. Methods ‘trf’ and ‘dogbox’ do not count function calls for numerical Jacobian approximation, as opposed to ‘lm’ method.
fvecThe residual values evaluated at the solution, for a 1-D sigma this is
(f(x, *popt) - ydata)/sigma.fjacA permutation of the R matrix of a QR factorization of the final approximate Jacobian matrix, stored column wise. Together with ipvt, the covariance of the estimate can be approximated. Method ‘lm’ only provides this information.
ipvtAn integer array of length N which defines a permutation matrix, p, such that fjac*p = q*r, where r is upper triangular with diagonal elements of nonincreasing magnitude. Column j of p is column ipvt(j) of the identity matrix. Method ‘lm’ only provides this information.
qtfThe vector (transpose(q) * fvec). Method ‘lm’ only provides this information.
Added in version 1.9.
- mesgstr (returned only if full_output is True)
A string message giving information about the solution.
Added in version 1.9.
- ierint (returned only if full_output is True)
An integer flag. If it is equal to 1, 2, 3 or 4, the solution was found. Otherwise, the solution was not found. In either case, the optional output variable mesg gives more information.
Added in version 1.9.
- Raises:
- ValueError
if either ydata or xdata contain NaNs, or if incompatible options are used.
- RuntimeError
if the least-squares minimization fails.
- TypeError
if the number of data points is fewer than the number of parameters
- OptimizeWarning
if covariance of the parameters can not be estimated.
See also
least_squaresMinimize the sum of squares of nonlinear functions.
scipy.stats.linregressCalculate a linear least squares regression for two sets of measurements.
Notes
Users should ensure that inputs xdata, ydata, and the output of f are
float64, or else the optimization may return incorrect results.With
method='lm', the algorithm uses the Levenberg-Marquardt algorithm throughleastsq. Note that this algorithm can only deal with unconstrained problems.Box constraints can be handled by methods ‘trf’ and ‘dogbox’. Refer to the docstring of
least_squaresfor more information.Parameters to be fitted must have similar scale. Differences of multiple orders of magnitude can lead to incorrect results. For the ‘trf’ and ‘dogbox’ methods, the x_scale keyword argument can be used to scale the parameters.
curve_fitis for local optimization of parameters to minimize the sum of squares of residuals. For global optimization, other choices of objective function, and other advanced features, consider using SciPy’s Global optimization tools or the LMFIT package.References
[1]K. Vugrin et al. Confidence region estimation techniques for nonlinear regression in groundwater flow: Three case studies. Water Resources Research, Vol. 43, W03423, DOI:10.1029/2005WR004804
Examples
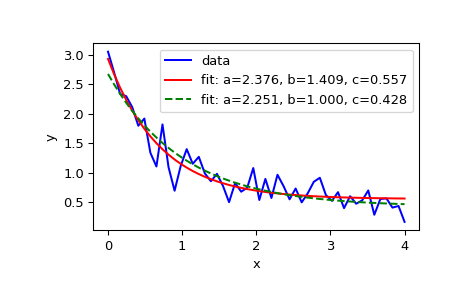
>>> import numpy as np >>> import matplotlib.pyplot as plt >>> from scipy.optimize import curve_fit
>>> def func(x, a, b, c): ... return a * np.exp(-b * x) + c
Define the data to be fit with some noise:
>>> xdata = np.linspace(0, 4, 50) >>> y = func(xdata, 2.5, 1.3, 0.5) >>> rng = np.random.default_rng() >>> y_noise = 0.2 * rng.normal(size=xdata.size) >>> ydata = y + y_noise >>> plt.plot(xdata, ydata, 'b-', label='data')
Fit for the parameters a, b, c of the function func:
>>> popt, pcov = curve_fit(func, xdata, ydata) >>> popt array([2.56274217, 1.37268521, 0.47427475]) >>> plt.plot(xdata, func(xdata, *popt), 'r-', ... label='fit: a=%5.3f, b=%5.3f, c=%5.3f' % tuple(popt))
Constrain the optimization to the region of
0 <= a <= 3,0 <= b <= 1and0 <= c <= 0.5:>>> popt, pcov = curve_fit(func, xdata, ydata, bounds=(0, [3., 1., 0.5])) >>> popt array([2.43736712, 1. , 0.34463856]) >>> plt.plot(xdata, func(xdata, *popt), 'g--', ... label='fit: a=%5.3f, b=%5.3f, c=%5.3f' % tuple(popt))
>>> plt.xlabel('x') >>> plt.ylabel('y') >>> plt.legend() >>> plt.show()
For reliable results, the model func should not be overparametrized; redundant parameters can cause unreliable covariance matrices and, in some cases, poorer quality fits. As a quick check of whether the model may be overparameterized, calculate the condition number of the covariance matrix:
>>> np.linalg.cond(pcov) 34.571092161547405 # may vary
The value is small, so it does not raise much concern. If, however, we were to add a fourth parameter
dto func with the same effect asa:>>> def func2(x, a, b, c, d): ... return a * d * np.exp(-b * x) + c # a and d are redundant >>> popt, pcov = curve_fit(func2, xdata, ydata) >>> np.linalg.cond(pcov) 1.13250718925596e+32 # may vary
Such a large value is cause for concern. The diagonal elements of the covariance matrix, which is related to uncertainty of the fit, gives more information:
>>> np.diag(pcov) array([1.48814742e+29, 3.78596560e-02, 5.39253738e-03, 2.76417220e+28]) # may vary
Note that the first and last terms are much larger than the other elements, suggesting that the optimal values of these parameters are ambiguous and that only one of these parameters is needed in the model.
If the optimal parameters of f differ by multiple orders of magnitude, the resulting fit can be inaccurate. Sometimes,
curve_fitcan fail to find any results:>>> ydata = func(xdata, 500000, 0.01, 15) >>> try: ... popt, pcov = curve_fit(func, xdata, ydata, method = 'trf') ... except RuntimeError as e: ... print(e) Optimal parameters not found: The maximum number of function evaluations is exceeded.
If parameter scale is roughly known beforehand, it can be defined in x_scale argument:
>>> popt, pcov = curve_fit(func, xdata, ydata, method = 'trf', ... x_scale = [1000, 1, 1]) >>> popt array([5.00000000e+05, 1.00000000e-02, 1.49999999e+01])