Maximum entropy models (scipy.maxentropy)¶
Routines for fitting maximum entropy models¶
Contains two classes for fitting maximum entropy models (also known as “exponential family” models) subject to linear constraints on the expectations of arbitrary feature statistics. One class, “model”, is for small discrete sample spaces, using explicit summation. The other, “bigmodel”, is for sample spaces that are either continuous (and perhaps high-dimensional) or discrete but too large to sum over, and uses importance sampling. conditional Monte Carlo methods.
The maximum entropy model has exponential form
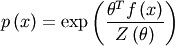
with a real parameter vector theta of the same length as the feature statistic f(x), For more background, see, for example, Cover and Thomas (1991), Elements of Information Theory.
See the file bergerexample.py for a walk-through of how to use these routines when the sample space is small enough to be enumerated.
See bergerexamplesimulated.py for a a similar walk-through using simulation.
Copyright: Ed Schofield, 2003-2006 License: BSD-style (see LICENSE.txt in main source directory)
Modules¶
| maxentropy | |
| maxentutils | Utility routines for the maximum entropy module. |
Classes¶
| DivergenceError(message) | Exception raised if the entropy dual has no finite minimum. |
| basemodel() | A base class providing generic functionality for both small and large maximum entropy models. |
| bigmodel() | A maximum-entropy (exponential-form) model on a large sample space. |
| conditionalmodel(F, counts, numcontexts) | A conditional maximum-entropy (exponential-form) model p(x|w) on a discrete sample space. |
| model([f, samplespace]) | A maximum-entropy (exponential-form) model on a discrete sample space. |
Functions¶
| arrayexp(x) | Returns the elementwise antilog of the real array x. |
| arrayexpcomplex | |
| columnmeans(A) | This is a wrapper for general dense or sparse dot products. |
| columnvariances(A) | This is a wrapper for general dense or sparse dot products. |
| densefeaturematrix | |
| densefeatures | |
| dotprod | |
| flatten(a) | Flattens the sparse matrix or dense array/matrix ‘a’ into a |
| innerprod(A, v) | This is a wrapper around general dense or sparse dot products. |
| innerprodtranspose(A, v) | This is a wrapper around general dense or sparse dot products. |
| logsumexp(a) | Compute the log of the sum of exponentials log(e^{a_1}+...e^{a_n}) |
| logsumexp_naive | |
| robustlog | |
| rowmeans | |
| sample_wr | |
| sparsefeaturematrix(f, sample[, format]) | Returns an (m x n) sparse matrix of non-zero evaluations of the scalar or vector functions f_1,...,f_m in the list f at the points x_1,...,x_n in the sequence ‘sample’. |
| sparsefeatures |
Models¶
- class scipy.maxentropy.basemodel¶
A base class providing generic functionality for both small and large maximum entropy models. Cannot be instantiated.
Methods
beginlogging clearcache crossentropy dual endlogging entropydual fit grad log logparams normconst reset setcallback setparams setsmooth
| basemodel.beginlogging(filename[, freq]) | Enable logging params for each fn evaluation to files named ‘filename.freq.pickle’, ‘filename.(2*freq).pickle’, ... |
| basemodel.endlogging() | Stop logging param values whenever setparams() is called. |
| basemodel.clearcache() | Clears the interim results of computations depending on the |
| basemodel.crossentropy(fx[, log_prior_x, base]) | Returns the cross entropy H(q, p) of the empirical |
| basemodel.dual([params, ignorepenalty, ...]) | Computes the Lagrangian dual L(theta) of the entropy of the |
| basemodel.fit(K[, algorithm]) | Fit the maxent model p whose feature expectations are given |
| basemodel.grad([params, ignorepenalty]) | Computes or estimates the gradient of the entropy dual. |
| basemodel.log(params) | This method is called every iteration during the optimization process. |
| basemodel.logparams() | Saves the model parameters if logging has been |
| basemodel.normconst() | Returns the normalization constant, or partition function, for the current model. |
| basemodel.reset([numfeatures]) | Resets the parameters self.params to zero, clearing the cache variables dependent on them. |
| basemodel.setcallback([callback, ...]) | Sets callback functions to be called every iteration, every function evaluation, or every gradient evaluation. |
| basemodel.setparams(params) | Set the parameter vector to params, replacing the existing parameters. |
| basemodel.setsmooth(sigma) | Specifies that the entropy dual and gradient should be computed with a quadratic penalty term on magnitude of the parameters. |
- class scipy.maxentropy.model(f=None, samplespace=None)¶
A maximum-entropy (exponential-form) model on a discrete sample space.
Methods
| model.expectations() | The vector E_p[f(X)] under the model p_params of the vector of |
| model.lognormconst() | Compute the log of the normalization constant (partition |
| model.logpmf() | Returns an array indexed by integers representing the |
| model.pmf_function([f]) | Returns the pmf p_theta(x) as a function taking values on the model’s sample space. |
| model.setfeaturesandsamplespace(f, samplespace) | Creates a new matrix self.F of features f of all points in the |
- class scipy.maxentropy.bigmodel¶
A maximum-entropy (exponential-form) model on a large sample space.
The model expectations are not computed exactly (by summing or integrating over a sample space) but approximately (by Monte Carlo estimation). Approximation is necessary when the sample space is too large to sum or integrate over in practice, like a continuous sample space in more than about 4 dimensions or a large discrete space like all possible sentences in a natural language.
Approximating the expectations by sampling requires an instrumental distribution that should be close to the model for fast convergence. The tails should be fatter than the model.
Methods
beginlogging clearcache crossentropy dual endlogging entropydual estimate expectations fit grad log lognormconst logparams logpdf normconst pdf pdf_function resample reset setcallback setparams setsampleFgen setsmooth settestsamples stochapprox test([label, verbose, extra_argv, doctests, ...]) Run tests for module using nose.
| bigmodel.estimate() | This function approximates both the feature expectation vector |
| bigmodel.logpdf(fx[, log_prior_x]) | Returns the log of the estimated density p(x) = p_theta(x) at the point x. |
| bigmodel.pdf(fx) | Returns the estimated density p_theta(x) at the point x with feature statistic fx = f(x). |
| bigmodel.pdf_function() | Returns the estimated density p_theta(x) as a function p(f) taking a vector f = f(x) of feature statistics at any point x. |
| bigmodel.resample() | (Re)samples the matrix F of sample features. |
| bigmodel.setsampleFgen(sampler[, staticsample]) | Initializes the Monte Carlo sampler to use the supplied |
| bigmodel.settestsamples(F_list, logprob_list) | Requests that the model be tested every ‘testevery’ iterations |
| bigmodel.stochapprox(K) | Tries to fit the model to the feature expectations K using |
| bigmodel.test() | Estimate the dual and gradient on the external samples, keeping track of the parameters that yield the minimum such dual. |
- class scipy.maxentropy.conditionalmodel(F, counts, numcontexts)¶
A conditional maximum-entropy (exponential-form) model p(x|w) on a discrete sample space.
This is useful for classification problems: given the context w, what is the probability of each class x?
The form of such a model is:
p(x | w) = exp(theta . f(w, x)) / Z(w; theta)
where Z(w; theta) is a normalization term equal to:
Z(w; theta) = sum_x exp(theta . f(w, x)).
The sum is over all classes x in the set Y, which must be supplied to the constructor as the parameter ‘samplespace’.
Such a model form arises from maximizing the entropy of a conditional model p(x | w) subject to the constraints:
K_i = E f_i(W, X)
where the expectation is with respect to the distribution:
q(w) p(x | w)
where q(w) is the empirical probability mass function derived from observations of the context w in a training set. Normally the vector K = {K_i} of expectations is set equal to the expectation of f_i(w, x) with respect to the empirical distribution.
This method minimizes the Lagrangian dual L of the entropy, which is defined for conditional models as:
L(theta) = sum_w q(w) log Z(w; theta) - sum_{w,x} q(w,x) [theta . f(w,x)]Note that both sums are only over the training set {w,x}, not the entire sample space, since q(w,x) = 0 for all w,x not in the training set.
The partial derivatives of L are:
dL / dtheta_i = K_i - E f_i(X, Y)
where the expectation is as defined above.
Methods
| conditionalmodel.dual([params, ignorepenalty]) | The entropy dual function is defined for conditional models as |
| conditionalmodel.expectations() | The vector of expectations of the features with respect to the |
| conditionalmodel.fit([algorithm]) | Fits the conditional maximum entropy model subject to the |
| conditionalmodel.lognormconst() | Compute the elementwise log of the normalization constant |
| conditionalmodel.logpmf() | Returns a (sparse) row vector of logarithms of the conditional probability mass function (pmf) values p(x | c) for all pairs (c, x), where c are contexts and x are points in the sample space. |
Utilities¶
Utility routines for the maximum entropy module.
Most of them are either Python replacements for the corresponding Fortran routines or wrappers around matrices to allow the maxent module to manipulate ndarrays, scipy sparse matrices, and PySparse matrices a common interface.
Perhaps the logsumexp() function belongs under the utils/ branch where other modules can access it more easily.
Copyright: Ed Schofield, 2003-2006 License: BSD-style (see LICENSE.txt in main source directory)
| arrayexp(x) | Returns the elementwise antilog of the real array x. |
| arrayexpcomplex(x) | Returns the elementwise antilog of the vector x. |
| columnmeans(A) | This is a wrapper for general dense or sparse dot products. |
| columnvariances(A) | This is a wrapper for general dense or sparse dot products. |
| densefeaturematrix(f, sample) | Returns an (m x n) dense array of non-zero evaluations of the |
| densefeatures(f, x) | Returns a dense array of non-zero evaluations of the functions fi |
| dotprod(u, v) | This is a wrapper around general dense or sparse dot products. |
| flatten(a) | Flattens the sparse matrix or dense array/matrix ‘a’ into a |
| innerprod(A, v) | This is a wrapper around general dense or sparse dot products. |
| innerprodtranspose(A, v) | This is a wrapper around general dense or sparse dot products. |
| logsumexp(a) | Compute the log of the sum of exponentials log(e^{a_1}+...e^{a_n}) |
| logsumexp_naive(values) | For testing logsumexp(). |
| robustlog(x) | Returns log(x) if x > 0, the complex log cmath.log(x) if x < 0, |
| rowmeans(A) | This is a wrapper for general dense or sparse dot products. |
| sample_wr(population, k) | Chooses k random elements (with replacement) from a population. |
| sparsefeaturematrix(f, sample[, format]) | Returns an (m x n) sparse matrix of non-zero evaluations of the scalar or vector functions f_1,...,f_m in the list f at the points x_1,...,x_n in the sequence ‘sample’. |
| sparsefeatures(f, x[, format]) | Returns an Mx1 sparse matrix of non-zero evaluations of the |
