Beyond the Basics¶
Iterating over elements in the array¶
Basic Iteration¶
One common algorithmic requirement is to be able to walk over all elements in a multidimensional array. The array iterator object makes this easy to do in a generic way that works for arrays of any dimension. Naturally, if you know the number of dimensions you will be using, then you can always write nested for loops to accomplish the iteration. If, however, you want to write code that works with any number of dimensions, then you can make use of the array iterator. An array iterator object is returned when accessing the .flat attribute of an array.
Basic usage is to call PyArray_IterNew ( array ) where array is an ndarray object (or one of its sub-classes). The returned object is an array-iterator object (the same object returned by the .flat attribute of the ndarray). This object is usually cast to PyArrayIterObject* so that its members can be accessed. The only members that are needed are iter->size which contains the total size of the array, iter->index, which contains the current 1-d index into the array, and iter->dataptr which is a pointer to the data for the current element of the array. Sometimes it is also useful to access iter->ao which is a pointer to the underlying ndarray object.
After processing data at the current element of the array, the next element of the array can be obtained using the macro PyArray_ITER_NEXT ( iter ). The iteration always proceeds in a C-style contiguous fashion (last index varying the fastest). The PyArray_ITER_GOTO ( iter, destination ) can be used to jump to a particular point in the array, where destination is an array of npy_intp data-type with space to handle at least the number of dimensions in the underlying array. Occasionally it is useful to use PyArray_ITER_GOTO1D ( iter, index ) which will jump to the 1-d index given by the value of index. The most common usage, however, is given in the following example.
PyObject *obj; /* assumed to be some ndarray object */
PyArrayIterObject *iter;
...
iter = (PyArrayIterObject *)PyArray_IterNew(obj);
if (iter == NULL) goto fail; /* Assume fail has clean-up code */
while (iter->index < iter->size) {
/* do something with the data at it->dataptr */
PyArray_ITER_NEXT(it);
}
...
You can also use PyArrayIter_Check ( obj ) to ensure you have an iterator object and PyArray_ITER_RESET ( iter ) to reset an iterator object back to the beginning of the array.
It should be emphasized at this point that you may not need the array iterator if your array is already contiguous (using an array iterator will work but will be slower than the fastest code you could write). The major purpose of array iterators is to encapsulate iteration over N-dimensional arrays with arbitrary strides. They are used in many, many places in the NumPy source code itself. If you already know your array is contiguous (Fortran or C), then simply adding the element- size to a running pointer variable will step you through the array very efficiently. In other words, code like this will probably be faster for you in the contiguous case (assuming doubles).
npy_intp size;
double *dptr; /* could make this any variable type */
size = PyArray_SIZE(obj);
dptr = PyArray_DATA(obj);
while(size--) {
/* do something with the data at dptr */
dptr++;
}
Iterating over all but one axis¶
A common algorithm is to loop over all elements of an array and perform some function with each element by issuing a function call. As function calls can be time consuming, one way to speed up this kind of algorithm is to write the function so it takes a vector of data and then write the iteration so the function call is performed for an entire dimension of data at a time. This increases the amount of work done per function call, thereby reducing the function-call over-head to a small(er) fraction of the total time. Even if the interior of the loop is performed without a function call it can be advantageous to perform the inner loop over the dimension with the highest number of elements to take advantage of speed enhancements available on micro- processors that use pipelining to enhance fundmental operations.
The PyArray_IterAllButAxis ( array, &dim ) constructs an
iterator object that is modified so that it will not iterate over the
dimension indicated by dim. The only restriction on this iterator
object, is that the PyArray_Iter_GOTO1D ( it, ind ) macro
cannot be used (thus flat indexing won’t work either if you pass this
object back to Python — so you shouldn’t do this). Note that the
returned object from this routine is still usually cast to
PyArrayIterObject *. All that’s been done is to modify the strides
and dimensions of the returned iterator to simulate iterating over
array[...,0,...] where 0 is placed on the
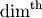 dimension. If dim is negative, then
the dimension with the largest axis is found and used.
dimension. If dim is negative, then
the dimension with the largest axis is found and used.
Iterating over multiple arrays¶
Very often, it is desireable to iterate over several arrays at the same time. The universal functions are an example of this kind of behavior. If all you want to do is iterate over arrays with the same shape, then simply creating several iterator objects is the standard procedure. For example, the following code iterates over two arrays assumed to be the same shape and size (actually obj1 just has to have at least as many total elements as does obj2):
/* It is already assumed that obj1 and obj2
are ndarrays of the same shape and size.
*/
iter1 = (PyArrayIterObject *)PyArray_IterNew(obj1);
if (iter1 == NULL) goto fail;
iter2 = (PyArrayIterObject *)PyArray_IterNew(obj2);
if (iter2 == NULL) goto fail; /* assume iter1 is DECREF'd at fail */
while (iter2->index < iter2->size) {
/* process with iter1->dataptr and iter2->dataptr */
PyArray_ITER_NEXT(iter1);
PyArray_ITER_NEXT(iter2);
}
Broadcasting over multiple arrays¶
When multiple arrays are involved in an operation, you may want to use the same broadcasting rules that the math operations ( i.e. the ufuncs) use. This can be done easily using the PyArrayMultiIterObject. This is the object returned from the Python command numpy.broadcast and it is almost as easy to use from C. The function PyArray_MultiIterNew ( n, ... ) is used (with n input objects in place of ... ). The input objects can be arrays or anything that can be converted into an array. A pointer to a PyArrayMultiIterObject is returned. Broadcasting has already been accomplished which adjusts the iterators so that all that needs to be done to advance to the next element in each array is for PyArray_ITER_NEXT to be called for each of the inputs. This incrementing is automatically performed by PyArray_MultiIter_NEXT ( obj ) macro (which can handle a multiterator obj as either a PyArrayMultiObject * or a PyObject *). The data from input number i is available using PyArray_MultiIter_DATA ( obj, i ) and the total (broadcasted) size as PyArray_MultiIter_SIZE ( obj). An example of using this feature follows.
mobj = PyArray_MultiIterNew(2, obj1, obj2);
size = PyArray_MultiIter_SIZE(obj);
while(size--) {
ptr1 = PyArray_MultiIter_DATA(mobj, 0);
ptr2 = PyArray_MultiIter_DATA(mobj, 1);
/* code using contents of ptr1 and ptr2 */
PyArray_MultiIter_NEXT(mobj);
}
The function PyArray_RemoveLargest ( multi ) can be used to take a multi-iterator object and adjust all the iterators so that iteration does not take place over the largest dimension (it makes that dimension of size 1). The code being looped over that makes use of the pointers will very-likely also need the strides data for each of the iterators. This information is stored in multi->iters[i]->strides.
There are several examples of using the multi-iterator in the NumPy source code as it makes N-dimensional broadcasting-code very simple to write. Browse the source for more examples.
Creating a new universal function¶
The umath module is a computer-generated C-module that creates many ufuncs. It provides a great many examples of how to create a universal function. Creating your own ufunc that will make use of the ufunc machinery is not difficult either. Suppose you have a function that you want to operate element-by-element over its inputs. By creating a new ufunc you will obtain a function that handles
- broadcasting
- N-dimensional looping
- automatic type-conversions with minimal memory usage
- optional output arrays
It is not difficult to create your own ufunc. All that is required is a 1-d loop for each data-type you want to support. Each 1-d loop must have a specific signature, and only ufuncs for fixed-size data-types can be used. The function call used to create a new ufunc to work on built-in data-types is given below. A different mechanism is used to register ufuncs for user-defined data-types.
- PyObject *PyUFunc_FromFuncAndData(PyUFuncGenericFunction* func, void** data, char* types, int ntypes, int nin, int nout, int identity, char* name, char* doc, int check_return)¶
func
A pointer to an array of 1-d functions to use. This array must be at least ntypes long. Each entry in the array must be a PyUFuncGenericFunction function. This function has the following signature. An example of a valid 1d loop function is also given.
- void loop1d(char** args, npy_intp* dimensions, npy_intp* steps, void* data)¶
args
An array of pointers to the actual data for the input and output arrays. The input arguments are given first followed by the output arguments.
dimensions
A pointer to the size of the dimension over which this function is looping.
steps
A pointer to the number of bytes to jump to get to the next element in this dimension for each of the input and output arguments.
data
Arbitrary data (extra arguments, function names, etc. ) that can be stored with the ufunc and will be passed in when it is called.
static void double_add(char *args, npy_intp *dimensions, npy_intp *steps, void *extra) { npy_intp i; npy_intp is1=steps[0], is2=steps[1]; npy_intp os=steps[2], n=dimensions[0]; char *i1=args[0], *i2=args[1], *op=args[2]; for (i=0; i<n; i++) { *((double *)op) = *((double *)i1) + \ *((double *)i2); i1 += is1; i2 += is2; op += os; } }
data
An array of data. There should be ntypes entries (or NULL) — one for every loop function defined for this ufunc. This data will be passed in to the 1-d loop. One common use of this data variable is to pass in an actual function to call to compute the result when a generic 1-d loop (e.g. PyUFunc_d_d) is being used.
types
An array of type-number signatures (type char ). This array should be of size (nin+nout)*ntypes and contain the data-types for the corresponding 1-d loop. The inputs should be first followed by the outputs. For example, suppose I have a ufunc that supports 1 integer and 1 double 1-d loop (length-2 func and data arrays) that takes 2 inputs and returns 1 output that is always a complex double, then the types array would be
The bit-width names can also be used (e.g. NPY_INT32, NPY_COMPLEX128 ) if desired.
ntypes
The number of data-types supported. This is equal to the number of 1-d loops provided.
nin
The number of input arguments.
nout
The number of output arguments.
identity
Either PyUFunc_One, PyUFunc_Zero, PyUFunc_None. This specifies what should be returned when an empty array is passed to the reduce method of the ufunc.
name
A NULL -terminated string providing the name of this ufunc (should be the Python name it will be called).
doc
A documentation string for this ufunc (will be used in generating the response to {ufunc_name}.__doc__). Do not include the function signature or the name as this is generated automatically.
check_return
Not presently used, but this integer value does get set in the structure-member of similar name.
The returned ufunc object is a callable Python object. It should be placed in a (module) dictionary under the same name as was used in the name argument to the ufunc-creation routine. The following example is adapted from the umath module
static PyUFuncGenericFunction atan2_functions[]=\ {PyUFunc_ff_f, PyUFunc_dd_d, PyUFunc_gg_g, PyUFunc_OO_O_method}; static void* atan2_data[]=\ {(void *)atan2f,(void *) atan2, (void *)atan2l,(void *)"arctan2"}; static char atan2_signatures[]=\ {NPY_FLOAT, NPY_FLOAT, NPY_FLOAT, NPY_DOUBLE, NPY_DOUBLE, NPY_DOUBLE, NPY_LONGDOUBLE, NPY_LONGDOUBLE, NPY_LONGDOUBLE NPY_OBJECT, NPY_OBJECT, NPY_OBJECT}; ... /* in the module initialization code */ PyObject *f, *dict, *module; ... dict = PyModule_GetDict(module); ... f = PyUFunc_FromFuncAndData(atan2_functions, atan2_data, atan2_signatures, 4, 2, 1, PyUFunc_None, "arctan2", "a safe and correct arctan(x1/x2)", 0); PyDict_SetItemString(dict, "arctan2", f); Py_DECREF(f); ...
User-defined data-types¶
NumPy comes with 21 builtin data-types. While this covers a large majority of possible use cases, it is conceivable that a user may have a need for an additional data-type. There is some support for adding an additional data-type into the NumPy system. This additional data- type will behave much like a regular data-type except ufuncs must have 1-d loops registered to handle it separately. Also checking for whether or not other data-types can be cast “safely” to and from this new type or not will always return “can cast” unless you also register which types your new data-type can be cast to and from. Adding data-types is one of the less well-tested areas for NumPy 1.0, so there may be bugs remaining in the approach. Only add a new data-type if you can’t do what you want to do using the OBJECT or VOID data-types that are already available. As an example of what I consider a useful application of the ability to add data-types is the possibility of adding a data-type of arbitrary precision floats to NumPy.
Adding the new data-type¶
To begin to make use of the new data-type, you need to first define a new Python type to hold the scalars of your new data-type. It should be acceptable to inherit from one of the array scalars if your new type has a binary compatible layout. This will allow your new data type to have the methods and attributes of array scalars. New data- types must have a fixed memory size (if you want to define a data-type that needs a flexible representation, like a variable-precision number, then use a pointer to the object as the data-type). The memory layout of the object structure for the new Python type must be PyObject_HEAD followed by the fixed-size memory needed for the data- type. For example, a suitable structure for the new Python type is:
typedef struct {
PyObject_HEAD;
some_data_type obval;
/* the name can be whatever you want */
} PySomeDataTypeObject;
After you have defined a new Python type object, you must then define a new PyArray_Descr structure whose typeobject member will contain a pointer to the data-type you’ve just defined. In addition, the required functions in the “.f” member must be defined: nonzero, copyswap, copyswapn, setitem, getitem, and cast. The more functions in the “.f” member you define, however, the more useful the new data-type will be. It is very important to intialize unused functions to NULL. This can be achieved using PyArray_InitArrFuncs (f).
Once a new PyArray_Descr structure is created and filled with the needed information and useful functions you call PyArray_RegisterDataType (new_descr). The return value from this call is an integer providing you with a unique type_number that specifies your data-type. This type number should be stored and made available by your module so that other modules can use it to recognize your data-type (the other mechanism for finding a user-defined data-type number is to search based on the name of the type-object associated with the data-type using PyArray_TypeNumFromName ).
Registering a casting function¶
You may want to allow builtin (and other user-defined) data-types to be cast automatically to your data-type. In order to make this possible, you must register a casting function with the data-type you want to be able to cast from. This requires writing low-level casting functions for each conversion you want to support and then registering these functions with the data-type descriptor. A low-level casting function has the signature.
- void castfunc(void* from, void* to, npy_intp n, void* fromarr, void* toarr)¶
- Cast n elements from one type to another. The data to cast from is in a contiguous, correctly-swapped and aligned chunk of memory pointed to by from. The buffer to cast to is also contiguous, correctly-swapped and aligned. The fromarr and toarr arguments should only be used for flexible-element-sized arrays (string, unicode, void).
An example castfunc is:
static void
double_to_float(double *from, float* to, npy_intp n,
void* ig1, void* ig2);
while (n--) {
(*to++) = (double) *(from++);
}
This could then be registered to convert doubles to floats using the code:
doub = PyArray_DescrFromType(NPY_DOUBLE);
PyArray_RegisterCastFunc(doub, NPY_FLOAT,
(PyArray_VectorUnaryFunc *)double_to_float);
Py_DECREF(doub);
Registering coercion rules¶
By default, all user-defined data-types are not presumed to be safely castable to any builtin data-types. In addition builtin data-types are not presumed to be safely castable to user-defined data-types. This situation limits the ability of user-defined data-types to participate in the coercion system used by ufuncs and other times when automatic coercion takes place in NumPy. This can be changed by registering data-types as safely castable from a particlar data-type object. The function PyArray_RegisterCanCast (from_descr, totype_number, scalarkind) should be used to specify that the data-type object from_descr can be cast to the data-type with type number totype_number. If you are not trying to alter scalar coercion rules, then use PyArray_NOSCALAR for the scalarkind argument.
If you want to allow your new data-type to also be able to share in the scalar coercion rules, then you need to specify the scalarkind function in the data-type object’s “.f” member to return the kind of scalar the new data-type should be seen as (the value of the scalar is available to that function). Then, you can register data-types that can be cast to separately for each scalar kind that may be returned from your user-defined data-type. If you don’t register scalar coercion handling, then all of your user-defined data-types will be seen as PyArray_NOSCALAR.
Registering a ufunc loop¶
You may also want to register low-level ufunc loops for your data-type so that an ndarray of your data-type can have math applied to it seamlessly. Registering a new loop with exactly the same arg_types signature, silently replaces any previously registered loops for that data-type.
Before you can register a 1-d loop for a ufunc, the ufunc must be previously created. Then you call PyUFunc_RegisterLoopForType (...) with the information needed for the loop. The return value of this function is 0 if the process was successful and -1 with an error condition set if it was not successful.
- int PyUFunc_RegisterLoopForType(PyUFuncObject* ufunc, int usertype, PyUFuncGenericFunction function, int* arg_types, void* data)¶
ufunc
The ufunc to attach this loop to.
usertype
The user-defined type this loop should be indexed under. This number must be a user-defined type or an error occurs.
function
The ufunc inner 1-d loop. This function must have the signature as explained in Section 3 .
arg_types
(optional) If given, this should contain an array of integers of at least size ufunc.nargs containing the data-types expected by the loop function. The data will be copied into a NumPy-managed structure so the memory for this argument should be deleted after calling this function. If this is NULL, then it will be assumed that all data-types are of type usertype.
data
(optional) Specify any optional data needed by the function which will be passed when the function is called.
Subtyping the ndarray in C¶
One of the lesser-used features that has been lurking in Python since 2.2 is the ability to sub-class types in C. This facility is one of the important reasons for basing NumPy off of the Numeric code-base which was already in C. A sub-type in C allows much more flexibility with regards to memory management. Sub-typing in C is not difficult even if you have only a rudimentary understanding of how to create new types for Python. While it is easiest to sub-type from a single parent type, sub-typing from multiple parent types is also possible. Multiple inheritence in C is generally less useful than it is in Python because a restriction on Python sub-types is that they have a binary compatible memory layout. Perhaps for this reason, it is somewhat easier to sub-type from a single parent type.
All C-structures corresponding to Python objects must begin with PyObject_HEAD (or PyObject_VAR_HEAD). In the same way, any sub-type must have a C-structure that begins with exactly the same memory layout as the parent type (or all of the parent types in the case of multiple-inheritance). The reason for this is that Python may attempt to access a member of the sub-type structure as if it had the parent structure ( i.e. it will cast a given pointer to a pointer to the parent structure and then dereference one of it’s members). If the memory layouts are not compatible, then this attempt will cause unpredictable behavior (eventually leading to a memory violation and program crash).
One of the elements in PyObject_HEAD is a pointer to a type-object structure. A new Python type is created by creating a new type-object structure and populating it with functions and pointers to describe the desired behavior of the type. Typically, a new C-structure is also created to contain the instance-specific information needed for each object of the type as well. For example, &PyArray_Type is a pointer to the type-object table for the ndarray while a PyArrayObject * variable is a pointer to a particular instance of an ndarray (one of the members of the ndarray structure is, in turn, a pointer to the type- object table &PyArray_Type). Finally PyType_Ready (<pointer_to_type_object>) must be called for every new Python type.
Creating sub-types¶
To create a sub-type, a similar proceedure must be followed except only behaviors that are different require new entries in the type- object structure. All other entires can be NULL and will be filled in by PyType_Ready with appropriate functions from the parent type(s). In particular, to create a sub-type in C follow these steps:
If needed create a new C-structure to handle each instance of your type. A typical C-structure would be:
typedef _new_struct { PyArrayObject base; /* new things here */ } NewArrayObject;
Notice that the full PyArrayObject is used as the first entry in order to ensure that the binary layout of instances of the new type is identical to the PyArrayObject.
Fill in a new Python type-object structure with pointers to new functions that will over-ride the default behavior while leaving any function that should remain the same unfilled (or NULL). The tp_name element should be different.
Fill in the tp_base member of the new type-object structure with a pointer to the (main) parent type object. For multiple-inheritance, also fill in the tp_bases member with a tuple containing all of the parent objects in the order they should be used to define inheritance. Remember, all parent-types must have the same C-structure for multiple inheritance to work properly.
Call PyType_Ready (<pointer_to_new_type>). If this function returns a negative number, a failure occurred and the type is not initialized. Otherwise, the type is ready to be used. It is generally important to place a reference to the new type into the module dictionary so it can be accessed from Python.
More information on creating sub-types in C can be learned by reading PEP 253 (available at http://www.python.org/dev/peps/pep-0253).
Specific features of ndarray sub-typing¶
Some special methods and attributes are used by arrays in order to facilitate the interoperation of sub-types with the base ndarray type.
Note
XXX: some of the documentation below needs to be moved to the reference guide.
The __array_finalize__ method¶
- ndarray.__array_finalize__¶
Several array-creation functions of the ndarray allow specification of a particular sub-type to be created. This allows sub-types to be handled seamlessly in many routines. When a sub-type is created in such a fashion, however, neither the __new__ method nor the __init__ method gets called. Instead, the sub-type is allocated and the appropriate instance-structure members are filled in. Finally, the __array_finalize__ attribute is looked-up in the object dictionary. If it is present and not None, then it can be either a CObject containing a pointer to a PyArray_FinalizeFunc or it can be a method taking a single argument (which could be None).
If the __array_finalize__ attribute is a CObject, then the pointer must be a pointer to a function with the signature:
(int) (PyArrayObject *, PyObject *)
The first argument is the newly created sub-type. The second argument (if not NULL) is the “parent” array (if the array was created using slicing or some other operation where a clearly-distinguishable parent is present). This routine can do anything it wants to. It should return a -1 on error and 0 otherwise.
If the __array_finalize__ attribute is not None nor a CObject, then it must be a Python method that takes the parent array as an argument (which could be None if there is no parent), and returns nothing. Errors in this method will be caught and handled.
The __array_priority__ attribute¶
- ndarray.__array_priority__¶
- This attribute allows simple but flexible determination of which sub- type should be considered “primary” when an operation involving two or more sub-types arises. In operations where different sub-types are being used, the sub-type with the largest __array_priority__ attribute will determine the sub-type of the output(s). If two sub- types have the same __array_priority__ then the sub-type of the first argument determines the output. The default __array_priority__ attribute returns a value of 0.0 for the base ndarray type and 1.0 for a sub-type. This attribute can also be defined by objects that are not sub-types of the ndarray and can be used to determine which __array_wrap__ method should be called for the return output.
The __array_wrap__ method¶
- ndarray.__array_wrap__¶
- Any class or type can define this method which should take an ndarray argument and return an instance of the type. It can be seen as the opposite of the __array__ method. This method is used by the ufuncs (and other NumPy functions) to allow other objects to pass through. For Python >2.4, it can also be used to write a decorator that converts a function that works only with ndarrays to one that works with any type with __array__ and __array_wrap__ methods.

Table Of Contents
- Beyond the Basics